Data Processing - Python
Algorithm
Any
Use Cases
Any
Once you’ve uploaded your schema to Begin, it’s time to start processing your data. This step processes your user data, generates digital signatures, and uploads them to Begin’s platform. These signatures are used to create your customized A.I. model.
Before You Start
Before we can get started, you’ll need to make sure the following steps
- Make sure you have your license key and app ID ready from the settings page.
- You’ll need to have a schema uploaded to Begin. Follow these steps to get started.
- Once your schema is uploaded, create a project using that schema and you’ll be taken to the integration code page. You’re ready to start processing.
Install Begin’s Library
First, install Begin’s pip library by calling:
pip install beginai
This will initiate the installation process.
If using virtual environments, don’t forget to add beginai to the requirements.txt file as well.
Add Your Account Credentials
Next, open your Python editor and import the library; then initialize it with the app_id and license_key that you can find under your settings menu in your account.
import beginai as bg APP_ID = "APP_ID" LICENSE_KEY = "LICENSE_KEY" beginWorker = bg.BeginWorker(app_id=APP_ID, license_key=LICENSE_KEY)
Load Your Data
Now you’re good to load your users’ data for processing on your computer. Copy the code from your Integration Code page to your SDK
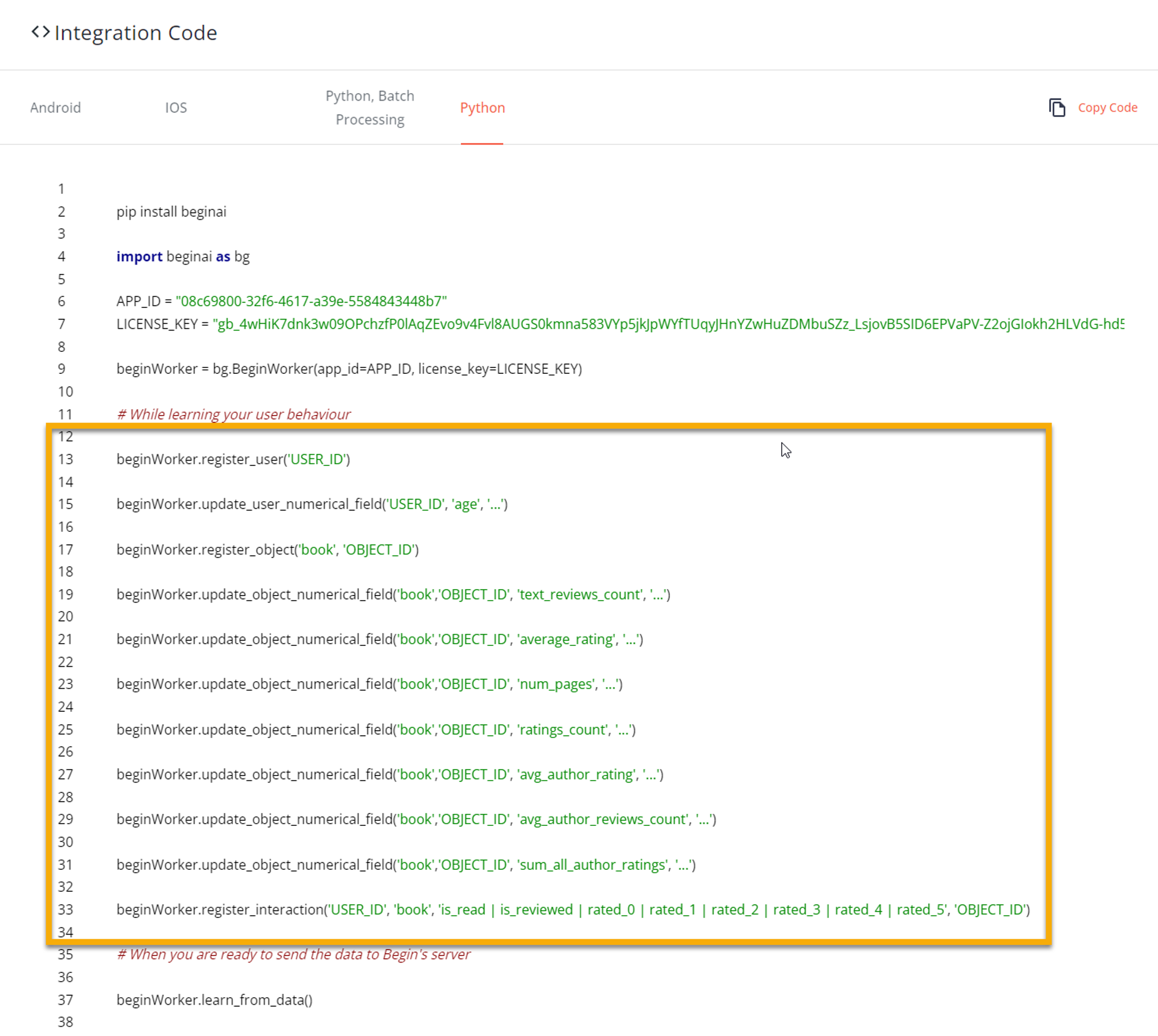
DON’T FORGET! All fields and interactions must be defined in the schema before they are used in the SDK.
For more information on what each field represents, refer to our field guide Integration Code Field Guide - Python
Start Learning
Once you’ve loaded your data, the final step is to send the following call:
begin_worker.learn_from_data()
When you write learn from data, anonymized and secure signatures are generated and sent to Begin platform to initiate the machine learning process.
RUNNING ON MULTIPLE PLATFORMS? You can process users from any SDK simultaneously. Once you make the above call, the system will merge the learnings across all platforms automatically.