Process on Device, Train Centrally
Begin’s Process on Device, Train in Cloud (PDTC) is Begin’s patented machine learning technique similar to Federated Learning. PDTC enables you to train fast, train privately, and with reduced bias.
How It Works
Data is mapped
First, you’ll provide a data schema describing important fields of data generated on your end device.
This schema includes the data points, their range, and interactions the user can have with the content (”positive”, “negative”, or “neutral”).
Begin’s SDK expresses this schema through our integration code. Add our integration code to your codebase to get learning.
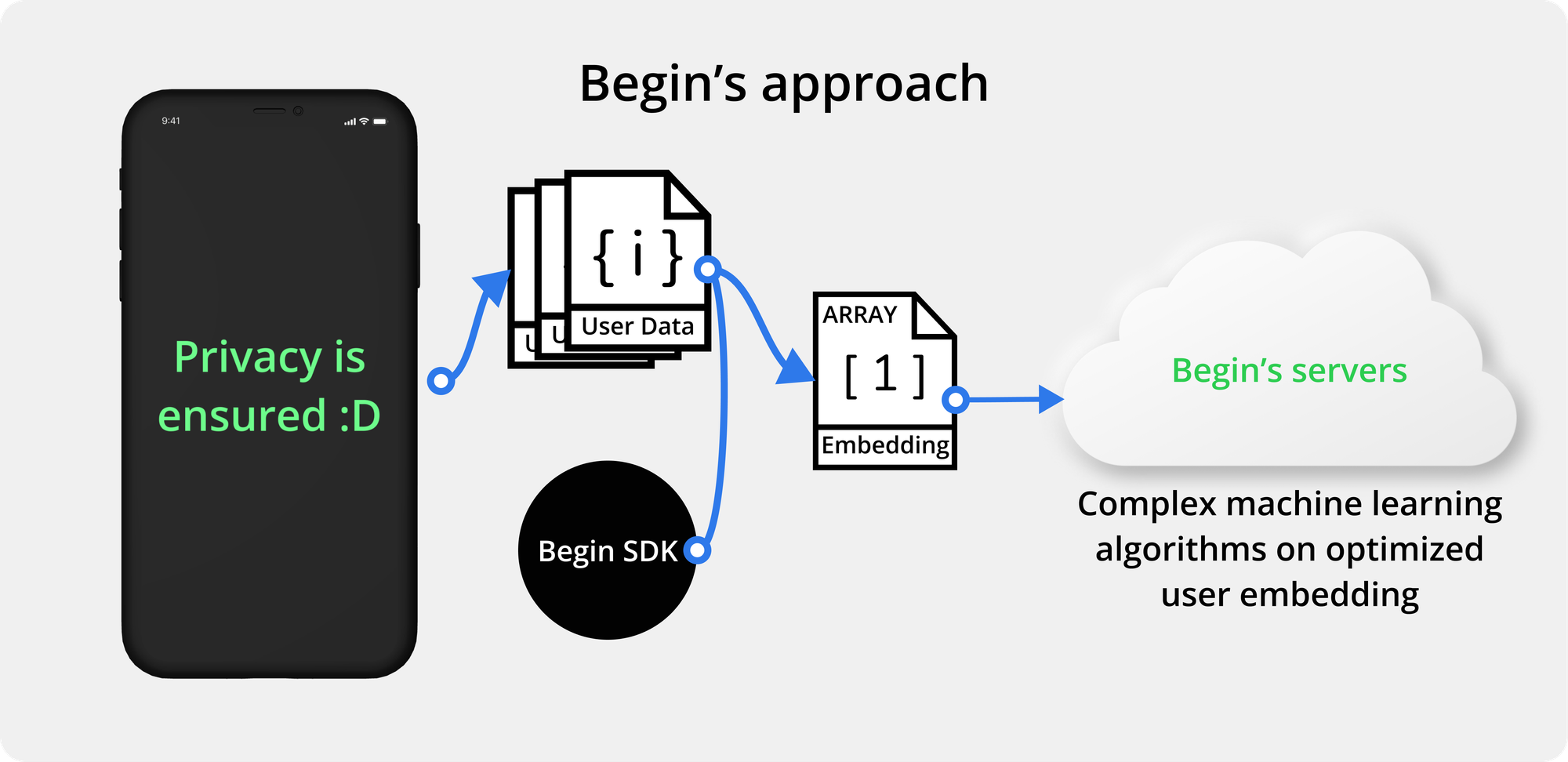
Data is processed
Once added, the SDK processes the data produced on the users’ devices as they interact with your application. This processing is coordinated via Begin’s servers to maximize learning while protecting data security.
Training starts
Once your user interacts with the app, a private Signature is generated. Signatures are a mathematical array of your users’ preferences, activity, and information, represented in a way that is only meaningful in relation to every other signature in the project. These signatures are pooled in Begin’s central server, where they collectively learn, adapt, and update the instructions for the next stage of learning.
Learning continues
These adaptations are pushed back to the users’ devices, where the signatures are updated, new interactions are generated, fake profiles are locked, new content is recommended, food is made, and experiences are improved.
This cycle continues, constantly growing and improving your users’ experience as they use the app.
Why PDTC?
Fast experimentation
As soon as you describe your schema and plug your SDK, you can begin testing your hypothesis in real-time. The connection is always live and secure, so testing, iterating, and reiterating your experiments take hours, rather than months.
Keep user data secure and private
Other machine learning techniques require your user data to be processed in the cloud. As your users’ data remains localized on its device, there’s no risk of privacy breaches or data leaks.
It works with any data set
As opposed to federated learning, PDTC is capable of inferring from data pools of any size. This allows your software to adapt from a single data set or a small pool of users to a scaled-up user base of millions.